Outline
- Gradient method: take the gradient of certain node with respect to the input image
- Vanilla gradient [https://arxiv.org/abs/1312.6034]
- Guided backpropagation [https://arxiv.org/abs/1412.6806]
- Integrated gradient [https://arxiv.org/abs/1703.01365]
- Visual backpropagation [https://arxiv.org/abs/1611.05418]
- Layer-wise relevance propagation
- Class activation mapping
- Gradient-weighted class activation mapping
- Deconvolution
- Activation maximization method: find the input image that maximally activates a node
- Other ideas
- style transfer
- deep dream
Code
Vanilla gradient¶
$$SaliencyMap = gradient = \frac{\partial \text{output of a node}}{\partial \text{input image}}$$Guided gradient¶
$$SaliencyMap = gradient = \frac{\partial \text{output of a node}}{\partial \text{input image}}$$The formula of guided gradient is the same as that of vanilla gradient except that only positive gradients are allowed to backpropagrate. This means that only the node which has positive activation, $a^l_j >0$, and positive gradient, $\frac{\partial L}{\partial a^l_j} > 0$, let gradient through.
Integrated gradient¶
$$SaliencyMap = (x_i-x_i') \times \int_{\alpha=0}^{1} \frac{\partial F(x'+\alpha \times (x-x'))}{\partial x_i}\text{d}\alpha$$Integrated gradient is defined as the path integral of the gradient from a baseline image $x'$ to the target image $x$.
Visual gradient¶
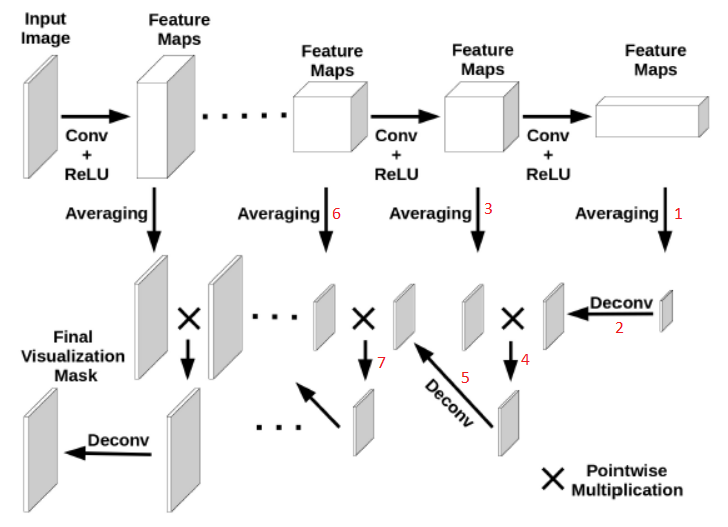
The SaliencyMap is obtained by multiplying the average activation maps of convolutonal layers. Deconvolution operation is used to increase the size of the activation map downstream to match up the size the activation map upstream.
comments powered by Disqus